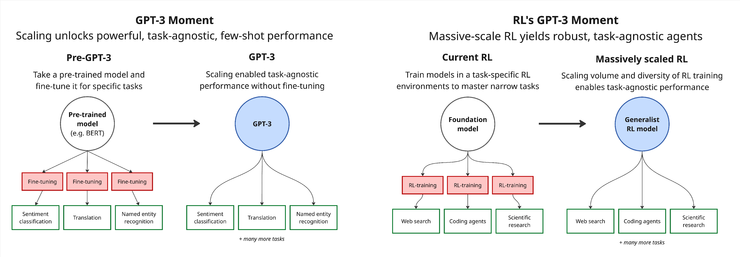
 最近,外国人开头的三个创始人撰写了一篇联合文章来做出大胆的决定。尽管RL可能需要指导“ GPT-3时刻”,但它需要培训等同于“花费在处理任务进行建模的时间”的数千年前。他们认为,当前的RL模型有明显的不便,例如概括功能不足和适应新任务的困难。这种情况实际上与GPT -3的前出现语言模型非常相似:它可以解决某些问题,但是很难迁移和扩展它。为了解决这个问题,他们提出了一种称为“复制培训”的新培训范式:在虚拟环境中模拟真实的软件操纵过程,例如使用浏览器,编写命令行任务的代码和管理。这种培训方法的优点是它具有明确的任务目标,明确的评分机制和训练数据可以自动生成。当然是不是全能的,例如任务的打开和测试设计中的一些挑战。但是,他们认为,复制训练是一条重要的途径,可以将RL模型推向通用智能,预计将导致功能性跳跃(例如GPT-3)。总而言之,Leifeng.com AI技术评论介绍了订购和呈现的原始文本,而没有改变其原始含义。当RL符合大量GPT-3的GPT-3时,这表明了重要事实。在此之前,您通常必须使用大型一般语料库来调整目标任务,以实现特定任务的最佳性能。当今的强化学习(RL)处于GPT-3前阶段。首先,在对象之前的大型模型,然后在某些高度专业的环境中对任务级别进行无聊的调整。但是,该策略具有其根本缺陷:其概括能力非常薄弱。当环境面对的环境很快就会崩溃模型略有变化。我们还相信RL正在引导“即时GPT-3”。换句话说,有几种培训方法可以从适应到数千个不同环境中进行大规模培训,促进具有很少能力和独立概括的代理商,并且可以灵活地适应新任务。但是,实现这一跳跃是创建具有规模和多样性的培训环境所需的全部,这远远超出了我们目前的状态。这是推动RL朝着能力爆炸的关键。应该实施多少个GPT-3 RL培训?但是,RL数据集的当前大小仍然非常有限。以DeepSeek-R1为例,培训数据包含大约600,000个数学问题。假设人类平均需要五分钟才能完成每个问题,那么一般的等效性大约是持续劳动的六年。相比GPT-3中的SED是根据正常的人工写作速度计算的,需要数十万年才能完成,但数字远离同一水平。另一方面,如果您想在先前切割要求的当前级别上投资于计算机功率,那么人类的家庭作业时间可能需要大约10,000年的时间(也就是说,建模所需的时间成为人类完成相同任务所需的时间)。 DeepSeek-R1在RL阶段使用了大约6e23拖船,并容纳了大约6年的模型处理任务。如果随后的训练保持相似的训练周期和诸如DeepSeek-R1之类的分组量表,则训练量表将增加到6E26花水平,这对应于大约6000年的处理任务。当然,随着任务多样性的越来越多,仍然无法确定RL将来是否会采用较大或更小的批量,或者将来的培训回合数量会增加。尽管由于缺乏相关的经验数据,对所需模型的任务时间的精确评估仍然很困难,但“ 10,000年”可能是合理的估计水平。要理解,可以将此培训量表与几个大型软件工程项目进行比较。 Ventan估计,他花了大约10,000年的人工工作,无论是SServer2008,GTA V还是Red Hat Linux 7.1。值得一提的是,从经济角度来看,在此规模上扩展RL的培训是Vicere。随着计算机在电力控制的一般培训成本上,RL培训预算预计将以与语言模型的捕获前相当的水平上升,预计该模型的性能有望显着提高,而不会导致总成本指数增长。真正的挑战是如何创建一个完全多样化并自动评估的RL环境。为了实现这一目标,您必须完全重新考虑RL环境的设计和构建。培训或复制解决方案?如果您需要为下一个令牌预测(下一个顶部的预测)手动为每个语言模型培训编写完整的培训语料库,请想象几乎无法完成。实际上,您之所以能够培训强大的语言模型的原因是,您可以直接使用大量的内容资源资源,例如书籍,学术文档,博客文章和有关Reddit的讨论来构建高质量的培训数据。同样,我们认为强化学习将带领GPT-3的独特时刻,而实现这一目标的关键可能是一种称为“复制训练”的新范式。中心思想允许AI模型复制现有的软件产品或特定特征。在第一阶段,您可以从相对简单的命令行工具开始。这些目标是清晰而紧凑的,例如实现某种类型的哈希或加密算法,适合早期培训。随着模型的功能的提高,复制培训任务的范围也可以扩展到更复杂的系统,例如Web应用程序,专业软件甚至更大的游戏。 leifeng.com(公共帐户:leifeng.com)每个副本培训任务提供详细的功能规范和参考实现。 AI模型的任务是与行为参考的实现完全相同的版本。这种方法的最大优点是评估是非常直接和客观的。该模型的退出与参考结果精确或不一致。明确的分数标准大大简化了训练过程中的评估机制,并提高了训练效率。 “复制培训”任务可能与日常软件开发有所不同,但针对当前AI系统仍然具有较弱工程功能的重要链接。例如为了重现模型中的复杂算法,您必须严格遵守详细的规格,例如D Tools Dand Dand加密和解密的命令,包含数以万计的代码)。您必须具有以下中心特征:为避免逻辑或实施偏差,请严格根据规范实施指令。您可以识别和修复早期错误,并具有问题恢复的可靠特征。像开发了数周的人类工程师一样,将稳定的生产保持在长期且高度复杂的任务中,结果的质量是直接通过精确度衡量的。满足对困难和“几乎良好”的半终止产品的满足并不容易。这些特征的结合是建立可靠的高质量AI工程系统的基础。 “复制训练”的独特价值在于,它为模型提供了系统完美的途径E通过将真实的复杂系统降低到高强度,以前的能力。这不仅补充了当前AI系统的能力,而且还为培训一般使用剂的重要技术基础提供了重要的技术基础。我们预测,“复制培训”将成为AI培训的下一个中心范式。该判断来自AI当前发展的基本倾向。通过大量现有的人类创建数据自动构建了许多新任务。就像自然语言资源在互联网上广泛使用一样,软件本身也是大量高度结构化的材料。复制培训基于此前提,并提供了有效地生成复杂任务并迁移到End -End -End开发功能的AI的可扩展且自动化的形式。这意味着每个人都可以独立完成软件项目。我是代理商。当然,这种方法不能免于挑战。例如,如何c重新有效而全面的证据仍然是一个相当大的工程问题,并且通常需要大量的手动投资。此外,从一种形式的形式中,副本培训略有“人造”,尽管每日软件开发完全复制现有软件并不常见,但是存在诸如携带软件,重建继承系统和“清洁室”等方案。但是,我们认为复制培训提供了一条清晰可行的途径,可能会使RL培训环境达到支持概括能力所需的大规模。这种范式可能是RL“ GPT-3”时刻的关键。这有助于该模型积累数千年的任务经验,因此,将GC的能力增生与坚实的任务无关。那么,复制训练是否是实施“全自动工作”的最终途径?在我看来不是。预计会产生我可以的系统基于详细的设计说明,N依赖性地完成复杂的软件项目,但是这些系统可能缺乏开放,灵活性和计划和在人类拥有的跨境场景中抽象地计划和提供高级管理的能力。即使AI将来成为主要程序员,也可能不可能从更广泛的意义上执行决策和协调任务。但是,我们认为复制培训可以成为关键的“桥梁”。我们对这种新范式的可能性和人员充满期望。
最近,外国人开头的三个创始人撰写了一篇联合文章来做出大胆的决定。尽管RL可能需要指导“ GPT-3时刻”,但它需要培训等同于“花费在处理任务进行建模的时间”的数千年前。他们认为,当前的RL模型有明显的不便,例如概括功能不足和适应新任务的困难。这种情况实际上与GPT -3的前出现语言模型非常相似:它可以解决某些问题,但是很难迁移和扩展它。为了解决这个问题,他们提出了一种称为“复制培训”的新培训范式:在虚拟环境中模拟真实的软件操纵过程,例如使用浏览器,编写命令行任务的代码和管理。这种培训方法的优点是它具有明确的任务目标,明确的评分机制和训练数据可以自动生成。当然是不是全能的,例如任务的打开和测试设计中的一些挑战。但是,他们认为,复制训练是一条重要的途径,可以将RL模型推向通用智能,预计将导致功能性跳跃(例如GPT-3)。总而言之,Leifeng.com AI技术评论介绍了订购和呈现的原始文本,而没有改变其原始含义。当RL符合大量GPT-3的GPT-3时,这表明了重要事实。在此之前,您通常必须使用大型一般语料库来调整目标任务,以实现特定任务的最佳性能。当今的强化学习(RL)处于GPT-3前阶段。首先,在对象之前的大型模型,然后在某些高度专业的环境中对任务级别进行无聊的调整。但是,该策略具有其根本缺陷:其概括能力非常薄弱。当环境面对的环境很快就会崩溃模型略有变化。我们还相信RL正在引导“即时GPT-3”。换句话说,有几种培训方法可以从适应到数千个不同环境中进行大规模培训,促进具有很少能力和独立概括的代理商,并且可以灵活地适应新任务。但是,实现这一跳跃是创建具有规模和多样性的培训环境所需的全部,这远远超出了我们目前的状态。这是推动RL朝着能力爆炸的关键。应该实施多少个GPT-3 RL培训?但是,RL数据集的当前大小仍然非常有限。以DeepSeek-R1为例,培训数据包含大约600,000个数学问题。假设人类平均需要五分钟才能完成每个问题,那么一般的等效性大约是持续劳动的六年。相比GPT-3中的SED是根据正常的人工写作速度计算的,需要数十万年才能完成,但数字远离同一水平。另一方面,如果您想在先前切割要求的当前级别上投资于计算机功率,那么人类的家庭作业时间可能需要大约10,000年的时间(也就是说,建模所需的时间成为人类完成相同任务所需的时间)。 DeepSeek-R1在RL阶段使用了大约6e23拖船,并容纳了大约6年的模型处理任务。如果随后的训练保持相似的训练周期和诸如DeepSeek-R1之类的分组量表,则训练量表将增加到6E26花水平,这对应于大约6000年的处理任务。当然,随着任务多样性的越来越多,仍然无法确定RL将来是否会采用较大或更小的批量,或者将来的培训回合数量会增加。尽管由于缺乏相关的经验数据,对所需模型的任务时间的精确评估仍然很困难,但“ 10,000年”可能是合理的估计水平。要理解,可以将此培训量表与几个大型软件工程项目进行比较。 Ventan估计,他花了大约10,000年的人工工作,无论是SServer2008,GTA V还是Red Hat Linux 7.1。值得一提的是,从经济角度来看,在此规模上扩展RL的培训是Vicere。随着计算机在电力控制的一般培训成本上,RL培训预算预计将以与语言模型的捕获前相当的水平上升,预计该模型的性能有望显着提高,而不会导致总成本指数增长。真正的挑战是如何创建一个完全多样化并自动评估的RL环境。为了实现这一目标,您必须完全重新考虑RL环境的设计和构建。培训或复制解决方案?如果您需要为下一个令牌预测(下一个顶部的预测)手动为每个语言模型培训编写完整的培训语料库,请想象几乎无法完成。实际上,您之所以能够培训强大的语言模型的原因是,您可以直接使用大量的内容资源资源,例如书籍,学术文档,博客文章和有关Reddit的讨论来构建高质量的培训数据。同样,我们认为强化学习将带领GPT-3的独特时刻,而实现这一目标的关键可能是一种称为“复制训练”的新范式。中心思想允许AI模型复制现有的软件产品或特定特征。在第一阶段,您可以从相对简单的命令行工具开始。这些目标是清晰而紧凑的,例如实现某种类型的哈希或加密算法,适合早期培训。随着模型的功能的提高,复制培训任务的范围也可以扩展到更复杂的系统,例如Web应用程序,专业软件甚至更大的游戏。 leifeng.com(公共帐户:leifeng.com)每个副本培训任务提供详细的功能规范和参考实现。 AI模型的任务是与行为参考的实现完全相同的版本。这种方法的最大优点是评估是非常直接和客观的。该模型的退出与参考结果精确或不一致。明确的分数标准大大简化了训练过程中的评估机制,并提高了训练效率。 “复制培训”任务可能与日常软件开发有所不同,但针对当前AI系统仍然具有较弱工程功能的重要链接。例如为了重现模型中的复杂算法,您必须严格遵守详细的规格,例如D Tools Dand Dand加密和解密的命令,包含数以万计的代码)。您必须具有以下中心特征:为避免逻辑或实施偏差,请严格根据规范实施指令。您可以识别和修复早期错误,并具有问题恢复的可靠特征。像开发了数周的人类工程师一样,将稳定的生产保持在长期且高度复杂的任务中,结果的质量是直接通过精确度衡量的。满足对困难和“几乎良好”的半终止产品的满足并不容易。这些特征的结合是建立可靠的高质量AI工程系统的基础。 “复制训练”的独特价值在于,它为模型提供了系统完美的途径E通过将真实的复杂系统降低到高强度,以前的能力。这不仅补充了当前AI系统的能力,而且还为培训一般使用剂的重要技术基础提供了重要的技术基础。我们预测,“复制培训”将成为AI培训的下一个中心范式。该判断来自AI当前发展的基本倾向。通过大量现有的人类创建数据自动构建了许多新任务。就像自然语言资源在互联网上广泛使用一样,软件本身也是大量高度结构化的材料。复制培训基于此前提,并提供了有效地生成复杂任务并迁移到End -End -End开发功能的AI的可扩展且自动化的形式。这意味着每个人都可以独立完成软件项目。我是代理商。当然,这种方法不能免于挑战。例如,如何c重新有效而全面的证据仍然是一个相当大的工程问题,并且通常需要大量的手动投资。此外,从一种形式的形式中,副本培训略有“人造”,尽管每日软件开发完全复制现有软件并不常见,但是存在诸如携带软件,重建继承系统和“清洁室”等方案。但是,我们认为复制培训提供了一条清晰可行的途径,可能会使RL培训环境达到支持概括能力所需的大规模。这种范式可能是RL“ GPT-3”时刻的关键。这有助于该模型积累数千年的任务经验,因此,将GC的能力增生与坚实的任务无关。那么,复制训练是否是实施“全自动工作”的最终途径?在我看来不是。预计会产生我可以的系统基于详细的设计说明,N依赖性地完成复杂的软件项目,但是这些系统可能缺乏开放,灵活性和计划和在人类拥有的跨境场景中抽象地计划和提供高级管理的能力。即使AI将来成为主要程序员,也可能不可能从更广泛的意义上执行决策和协调任务。但是,我们认为复制培训可以成为关键的“桥梁”。我们对这种新范式的可能性和人员充满期望。